 Published on JAVA exPress
(http://www.javaexpress.pl)
Published on JAVA exPress
(http://www.javaexpress.pl)
Maven 2 - jak ułatwić sobie pracę, cz. I
Rafał Kotusiewicz
Issue 2 (2008-12-06)
Zachęcony własnymi doświadczeniami z Mavenem 2 zapragnąłem podzielić się z Wami wiedzą, którą w ostatnich miesiącach zdobyłem na temat tego wspaniałego narzędzia. Dodam, że jeszcze rok temu byłem gorącym zwolennikiem Anta. Dzięki temu opiszę również sposób migracji projektu z Anta na Mavena – jeśli ma to oczywiście sens.
Założenie co do wiedzy czytelnika
Przystępując do czytania tego tekstu czytelnik powinien znać system operacyjny na tyle, żeby ustawić w nim zmienne środowiskowe i posłużyć się narzędziami do rozpakowania archiwów (zip lub tgz). Zakładam oczywiście, że wiedza ta jest na tyle niemagiczna, że każdy z Was ją posiada, a jeśli nie, to może posiąść w ciągu najbliższych kilku minut (jednak nie jest to przedmiotem naszych rozważań).
Instalacja Mavena
Aby zainstalować Maven w środowisku developerskim nie musi ono spełnić właściwie żadnych specjalnych wymagań poza dwoma podstawowymi. Po pierwsze do uruchomienie potrzebna jest Java w wersji 1.4 lub nowsza oraz wystarczająca ilość miejsca na dysku aby przechowywać repozytorium z bibliotekami. Dodam, że repozytorium w moim środowisku zajmuje około 200MB, myślę więc, że zarezerwowanie około 300-400MB z jednej strony zabezpieczy nasze potrzeby, a z drugiej nie będzie stanowić zbyt dużego obciążenia dla dysku (tym bardziej, że powierzchnia dysku jest stosunkowo tania). Jeśli maszyna, na której zamierzacie zainstalować Mavena spełnia te niezbyt wygórowane wymagania czas zabrać się za instalację.
Czynność to niemal oczywista więc poświecimy jej tak niewiele miejsca jak to możliwe. Ze strony http://maven.apache.org/download.html ściągamy archiwum z Maven 2.0.9 odpowiednie dla używanego systemu operacyjnego. Plik ma około 2MB więc powinno zająć to krótką chwilkę w zależności od łącza, którym dysponujemy. Ściągnięty plik rozpakowujemy do jakiegoś wygodnego dla nas katalogu (warto wybrać taki żeby unikać - kłopotliwych czasami - spacji w ścieżce), np. C:/apache-maven-2.0.9. Teraz należy zająć się ustawieniem zmiennych środowiskowych. Jeśli nie macie jeszcze ustawionej zmiennej JAVA_HOME, to najwyższy czas to uczynić. Warto oczywiście dodać katalog $JAVA_HOME/bin (lub %JAVA_HOME%/bin) do zmiennej $PATH (lub %PATH%), choć nie jest to oczywiście koniecznie dla poprawnej pracy z Mavenem. Mając już pewność, że JAVA_HOME ustawiona jest poprawnie i wskazuje na główny katalog z JDK możemy ustawić dwie kolejne. Zmienna M2_HOME (lub MAVEN_HOME ) musi wskazywać na główny katalog Mavena, czyli w naszym przykładzie C:/apache-maven-2.0.9. Teraz uaktualniamy zmienną PATH dodając do niej katalog M2_HOME/bin (lub MAVEN_HOME/bin). Sprawdzamy efekt poprzez ponowne otwarcie terminala (jeśli pracujemy z Windows) lub przeładowania środowiska (*nix, Mac OS X).
C:Documents and SettingsRafał>mvn --version
Maven version: 2.0.9
Java version: 1.5.0_16
OS name: "windows xp" version: "5.1" arch: "x86" Family: "windows"
Jeśli na waszych komputerach efekt jest taki sam to znaczy, że wszystko się udało. Jeżeli jednak są jakieś problemy, należy sprawdzić poprawność ustawienia zmiennych środowiskowych (za pomocą polecenia echo $ZMIENNA w terminalu). Jeśli problem objawia się wyświetleniem długiego stosu wyjątków, to być może archiwum z Mavenem zostało uszkodzone podczas transportu. Warto wtedy ściągnąć je ponownie wybierając inny serwer źródłowy. Jednak z doświadczenia wiem, że na tym etapie problemy jeśli się zdarzają to wynikają raczej z błędnych ustawień środowiska – tam też należy szukać ich przyczyn.
Pierwsze kroki
Aby zobaczyć jak łatwe jest korzystanie z Mavena, w kilka sekund utworzymy szkielet naszego pierwszego projektu, najpierw go utworzymy potem zaś zastanowimy się dokładnie co się stało i dlaczego. Wpisujemy w terminalu co następuje (zaznaczone pogrubionym tekstem):
C:DevJaveExpressMaven>mvn archetype:create
-DgroupId=com.javaexpress
-DartifactId=HelloMaven
[INFO] Scanning for projects...
[INFO] Searching repository for plugin with prefix: 'archetype'.
[INFO] ------------------------------------------------------------------------
[INFO] Building Maven Default Project
[INFO] task-segment: [archetype:create] (aggregator-style)
…
…
[INFO] BUILD SUCCESSFUL
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 7 seconds
[INFO] Finished at: Wed Sep 24 22:16:42 CEST 2008
[INFO] Final Memory: 8M/14M
[INFO] ------------------------------------------------------------------------
Najpierw należy pewnie wyjaśnić czego zażądaliśmy... Poprosiliśmy Mavena, aby utworzył dla nas szkielet standardowej aplikacji (pakowanej do jara) wraz z szablonem pliku opisującego nasz projekt. W sumie dużo i trwało to kilka sekund (za pierwszym razem może trwać nieco dłużej, ponieważ Maven potrzebne biblioteki ściąga ze zdalnego repozytorium do repozytorium lokalnego). Spójrzmy zatem co się pojawiło w wyniku naszych działań. W katalogu, w którym znajdowaliśmy się pojawił się katalog zgodny z wartością parametru artifactId, który podaliśmy tworząc projekt.
C:DevJaveExpressMaven>dir
...
2008-09-24 22:16 <DIR> .
2008-09-24 22:16 <DIR> ..
2008-09-24 22:16 <DIR> HelloMaven
0 plik(ów) 0 bajtów
3 katalog(ów) 50 311 876 608 bajtów wolnych
HelloMaven to nasz projekt. Gdy zajrzymy do katalogu, w którym się znajduje, natrafimy na plik pom.xml (do którego zawartości będziemy wielokrotnie wracać) oraz katalog src. Pełna zawartość aktualnie wygląda tak:
|- pom.xml
`- src
|- main
| `- java
| `- com
| `- javaexpress
| `- App.java
`- test
`- java
`- com
`- javaexpress
`- AppTest.java
Wstępnie wyjaśnię, że katalog src zawiera – jak można się domyśleć – źródła aplikacji i testów (zgodnie z założeniem, ze testy to część aplikacji) podzielone wg przeznaczenia ze wstępnie zarysowaną strukturą pakietów zgodną z wartością parametru groupId podaną podczas tworzenia szkieletu. Zanim przejdziemy dalej poddajmy drobnej edycji plik App.java. Zamieńmy znajdujący się tam wiersz:
System.out.println( "Hello World!" );
na bliższy duchowi naszej przykładowej aplikacji:
System.out.println( "Hello Maven!" );
Teraz znajdując się w katalogu aplikacji (tego, w którym znajduje się plik pom.xml) wywołujemy polecenie:
C:DevJaveExpressMavenHelloMaven>mvn package
[INFO] Scanning for projects...
[INFO] ------------------------------------------------------------------------
[INFO] Building HelloMaven
[INFO] task-segment: [package]
[INFO] ------------------------------------------------------------------------
[INFO] [resources:resources]
[INFO] Using default encoding to copy filtered resources.
[INFO] [compiler:compile]
[INFO] Compiling 1 source file to C:DevJaveExpressMavenHelloMaven argetclasses
[INFO] [resources:testResources]
[INFO] Using default encoding to copy filtered resources.
[INFO] [compiler:testCompile]
[INFO] Compiling 1 source file to C:DevJaveExpressMavenHelloMaven arget est-classes
[INFO] [surefire:test]
[INFO] Surefire report directory: C:DevJaveExpressMavenHelloMaven argetsurefire-reports
-------------------------------------------------------
T E S T S
-------------------------------------------------------
Running com.javaexpress.AppTest
Tests run: 1, Failures: 0, Errors: 0, Skipped: 0, Time elapsed: 0.093 sec
Results :
Tests run: 1, Failures: 0, Errors: 0, Skipped: 0
[INFO] [jar:jar]
[INFO] Building jar: C:DevJaveExpressMavenHelloMaven argetHelloMaven-1.0-SNAPSHOT.jar
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESSFUL
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 5 seconds
[INFO] Finished at: Thu Oct 16 11:43:39 CEST 2008
[INFO] Final Memory: 7M/13M
[INFO] ------------------------------------------------------------------------
Tym razem zostawimy cały listing, żeby wyjaśnić krok po kroku co się stało. Na początek Maven poszukuje pliku projektu (pom.xml), na podstawie którego może kontynuować swoje działanie. Znalazł go, więc informuje o przeprowadzanych czynnościach. Widzimy, że dostrzegł nasze pragnienie spakowania projektu, a żeby to zrobić musi przeprowadzić po kolei kilka faz swojego działania (o tym napiszę szerzej już za chwilę). Najpierw próbuje przetworzyć wszystkie zasoby, potem kompiluje pliki źródłowe Javy, potem przetwarza zasoby wymagane przez testy i kompiluje testy. Następnie uruchamia wszystkie testy i jako, że nie wystąpiły po drodze żadne problemy, pakuje całość do pliku jar. Aby upewnić się, że wszystko jest jak należy spróbujmy uruchomić program. Ale gdzie on jest?! – zapytacie. Otóż cały efekt pracy Mavena podczas budowania aplikacji znajduje się w katalogu target/ (tworzonym przez niego automatycznie) położonym na równi z katalogiem src. Tam należy szukać katalogu classes ze skompilowanymi plikami javy oraz pliku *.jar o nazwie dość rozbudowanej. Do nazwy wrócimy również niebawem. Tymczasem spróbujmy uruchomić program.
C:DevJaveExpressMavenHelloMaven>java -cp .;targetHelloMaven-1.0-SNAPSHOT.jar com.javaexpress.App
Hello Maven!
Działa jak należy, możemy więc wrócić do przeanalizowania prostego póki co pliku pom.xml. Jego aktualna zawartość wygląda mniej więcej tak:
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.javaexpress</groupId>
<artifactId>HelloMaven</artifactId>
<packaging>jar</packaging>
<version>1.0-SNAPSHOT</version>
<name>HelloMaven</name>
<url>http://maven.apache.org</url>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
</dependencies>
</project>
Jak widać na listingu, jest to plik w formacie XML i opisuje nasz projekt. W aktualnej wersji zawiera naprawdę niezbędną ilość informacji (pozostałe, jak katalog ze źródłami itp. Maven czerpie ze znanej sobie konwencji1) potrzebną do zbudowania projektu. Zacznijmy od góry. Elementy groupId oraz artifactId zawierają wartości podane przez nas podczas tworzenia projektu. Zatrzymajmy się więc by dokładnie wyjaśnić czym jest jedno i drugie. Grupa (reprezentowana przez groupId) jest ogólnym określeniem dla zestawu produktów, bibliotek czy też aplikacji, stanowiących razem pewną całość. Artefakt zaś (reprezentowany oczywiście przez element artefactId) to nazwa produktu w obrębie grupy. Zastanówmy się co to znaczy, by w przyszłości skorzystać z wniosków. Jeśli mamy aplikację, która składa się z trzech części: zestawu klas biznesowych (model aplikacji) oraz zestawu interfejsów DAO jako pojedynczej części, implementacji wspomnianych interfejsów oraz części klienckiej, np. aplikacji www, a całość stanowi pewną grupę logiczna, jeden właściwy produkt, to warto wszystkie te projekty umieścić w obrębie tej samej grupy (np. com.company.crm) a poszczególne części jako artefakty o nazwach np. crm-api, crm-dao-impl, crm-web. Kolejnym elementem jest wersja i wydaje mi się, że na tym etapie nie wymaga absolutnie żadnego komentarza (choć z wersjami związana jest pewna tradycja i funkcjonalność samego Mavena i warto wrócić później do tematu). Ważne natomiast jest, że efektem spakowania projektu będzie plik o nazwie domyślnie składającej się z elementów artefactId, version oraz packaging. W naszym wypadku:
HelloMaven-1.0-SNAPSHOT.jar
Zawartość elementu name pojawia się w konsoli, gdy uruchamiamy maven'a, aby zidentyfikować aktualnie przetwarzany projekt. Element url jest informacją o stronie domowej projektu. We właściwym czasie zobaczymy jak z tego skorzystać. Domyślnie jako strona domowa ustawiana jest strona Mavena. W tej chwili możemy ją tak pozostawić.
Ostatnim elementem, któremu przyjrzymy się teraz będzie wykaz zależności projektu. Wszystkie zależności objęte są wspólnym elementem dependencies, który zawiera wiele elementów dependency. Zależności to oczywiście biblioteki, z których korzystamy pisząc nasz kod. We wstępnie wygenerowanym pliku pom.xml widać jedną zależność, jest to biblioteka junit, którą wszyscy pewnie dobrze znają. Potrzebna jest tylko podczas testowania, co jest zaznaczone w elemencie scope. Zanim wyjaśnię czym jest scope, powiem skąd się biorą biblioteki i dlaczego nie ma katalogu lib w projekcie.
Zależności projektu
Każdy projekt, nad którym pracujemy (poza tymi naprawdę najprostszymi) posiada jakieś zewnętrzne zależności, np. biblioteki do obsługi skrótów, logowania itp. Nie inaczej będzie tym razem, naszą główną klasę wyposażymy w mechanizm logowania. Możemy korzystać z System.out.println(...), ale jak powszechnie wiadomo nie jest to dobry zwyczaj. Dlatego też wykażemy nieco finezji i wykorzystamy Logger dostępny na stronach apache.org. Jak zatem dołączyć bibliotekę do projektu? Właśnie w tym celu skorzystamy ze wspomnianego już elementu dependency. Za pomocą edytora otwieramy plik pom.xml i dodajemy następujący fragment:
…
<dependencies>
<dependency>
<groupId>commons-logging</groupId>
<artifactId>commons-logging</artifactId>
<version>1.1.1</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
</dependencies>
…
Skąd jednak wziąć te informacje? Skąd Maven będzie wiedział jak dołączyć wymaganą bibliotekę? Gdzie fizycznie znajduje się plik biblioteki? Mnóstwo pytań – trzeba na nie odpowiedzieć. Najpierw rozwieję wątpliwości dotyczące tego skąd się wspomniane biblioteki biorą. Otóż istnieją rozsiane po sieci repozytoria takich bibliotek, każde z nich jest uporządkowane właśnie zgodnie z podaną hierarchią. Najpierw według grup, potem według artefaktów i na koniec według wersji. Można przyjrzeć się repozytoriom np. pod adresem http://repo1.maven.org/maven2 lub http://mirrors.ibiblio.org/pub/mirrors/maven2. Zróbmy chwilkę przerwy i zajrzyjcie pod te adresy. Miło popatrzeć, ile wspaniałej pracy programistycznej zgromadzono w każdym z tych miejsc. Bezpośrednie przeglądanie tych repozytoriów jest jedną z metod poszukiwania zależności. Nie jest jednak metodą najlepszą. Znacznie wygodniej jest skorzystać z jednej z wyszukiwarek bibliotek. Jedną z dostępnych jest http://mvnrepository.com. Wyszukując logger do naszego przykładu (wiemy, że szukamy biblioteki commons-logging) w wyszukiwarce wpiszmy commons-logging. Biblioteka, której szukamy znajduje się na czwartej pozycji.
4. commons-logging » commons-logging
Spróbujmy objaśnić wynik tym bardziej, że na piątej pozycji mamy niezwykle podobny tekst.
5. commons-logging » commons-logging-api
Oczywiście pod każdym z wierszy wyniku znajduje się krótki opis pozycji. Nieprzypadkowo jest to zawartość elementu <description> z pliku pom.xml projektu (tutaj commons-logging). Cóż jednak odczytać z wierszy wyniku? Otóż po lewej stronie znaku » znajduje się nazwa grupy (groupId), po prawej zaś nazwa artefaktu (artifactId) elementu z listy dopasowanych do kryteriów wyszukiwania. Patrząc na opis jesteśmy w stanie zorientować się, że chodzi nam raczej o pozycję czwartą niż piątą. Kliknijmy więc w nazwę artefaktu aby przenieść się na listę dostępnych jego wersji. Na kolejnej stronie widać więcej szczegółów artefaktu oraz spodziewaną listę z wersjami (a także statystyki) i szablon elementu <dependency> gotów do skopiowania i wstawienia do pliku pom.xml naszego projektu. Jest to szablon sugerujący użycie najnowszej dostępnej wersji. Jeśli z jakichś powodów chcemy korzystać z wersji starszej możemy kliknąć w jedną ze znajdujących się na liście by przenieść się na kolejną stronę – tym razem z informacjami o tej wersji i otrzymać właściwy jej szablon.
Ostatnim dziś omawianym elementem jest scope. Definiuje on dwie rzeczy, po pierwsze dostępność klas z biblioteki dla klas projektu podczas kompilacji, testowania i uruchomienia oraz w zależności od sposobu pakowania projektu lub zastosowanych pluginów determinuje to czy zależność będzie dołączona do projektu czy też nie. Poniższe zestawienie - mam nadzieję - rozwieje wszystkie, lub chociaż większość, wątpliwości.
compile - Kompilacja, testowanie i uruchomienie. Biblioteka dostępna zawsze i dołączana do wynikowego artefaktu. Jest to domyślna wartość elementu scope ustawiana, jeśli zostanie on pominięty przy definicji zależności.
provided - Kompilacja i testowanie. Zakładamy, że biblioteka będzie dostarczona przez środowisko uruchomieniowe (kontener), nie jest więc dołączana (np. ServletAPI)
test - Kompilacja testów i testowanie. Dostępne tylko podczas kompilacji i uruchomienia testów.
runtime - Testowanie i uruchomienie. Biblioteka dostępna podczas uruchamiania testów oraz wymagana do działania aplikacji, jest więc dołączana do artefaktu wynikowego.
O konfigurowaniu zależności można napisać więcej, jednak myślę, że na tym etapie ta ilość informacji jest wystarczająca (co sugeruje, że w przyszłości będziemy do tego tematu wracać).
Teraz obiecana odpowiedź na pytanie „gdzie fizycznie znajdują się pliki bibliotek?” - bo przecież nie korzystamy przy każdej kompilacji z plików znajdujących się na zdalnych serwerach. Otóż nie, nie korzystamy z nich za każdym razem, tylko za pierwszym, czyli przy pierwszej potrzebie wykorzystania biblioteki. Odbywa się to tak - Maven poszukuje w lokalnym repozytorium (utworzonym podczas pierwszej próby utworzenia projektu) wskazanej biblioteki. Jeśli jej nie odnajdzie, ściąga z któregoś ze zdalnych repozytoriów i instaluje w przestrzenie naszego lokalnego. Katalog z lokalnym repozytorium znajduje się zwykle w katalogu .m2/repository znajdującym się w naszym domowym katalogu. Tam też można odnaleźć strukturę podobną do tej ze zdalnych repozytoriów.
Kolejna ważna sprawa dotycząca samych zależności. Otóż, nie wszystkie biblioteki są dostępne w publicznych repozytoriach. Powody są rożne, czasem kwestie licencyjne, a czasem są to zakupione od naszych dostawców fragmenty tworzonego systemu. A czasami po prostu korzystamy z jakiegoś leciwego kodu, którym po prostu nie ma się kto zająć i nie trafił dotąd do żadnego publicznego repozytorium. My jednak potrzebujemy tej biblioteki, a jak wspominałem nie mamy katalogu lib w projekcie (pomijam projekt webowy i katalog WEB-INF/lib, bo tam raczej się nie wrzuca żadnych plików, a nawet gdybyśmy to zrobili, to nie ma jak poinformować Mavena żeby tam czegoś szukał). Musimy taką bibliotekę zainstalować w naszym lokalnym repozytorium. Robimy to za pomocą Mavena i jego pluginu do instalacji artefaktów. Spójrzmy na przykład. Do projektu chcemy dołączyć bibliotekę super-tajny.jar (kosztowała 1999$ i licencja nie pozwala umieścić jej w publicznym repozytorium). Kopiujemy wspomniany plik jar do bieżącego katalogu (dla wygody, bo przecież równie dobrze można posłużyć się pełną ścieżką wskazując aktualne miejsce pobytu jara) i wykonujemy następujące polecenie (pamiętając czym jest groupId, artifactId oraz version dla tego pliku):
mvn install:install-file -Dfile=super-tajny.jar -DgroupId=com.dostawca.tajny
-DartifactId=super-tajny -Dversion=1.0
Teraz plik możemy już usunąć z bieżącego katalogu, przenieść się do katalogu z naszym projektem i wyedytować plik pom.xml dodające następujący kod :
<dependencies>
...
<dependency>
<groupId>com.dostawca.tajny</groupId>
<artifactId>super-tajny</artifactId>
<version>1.0</version>
<scope>runtime</scope><!-- lub inny w zalżności od potrzeb -->
</dependency>
…
</dependencies>
Fazy budowania projektu
Teraz, skoro już wiemy jak stworzyć projekt, jak dołączyć do niego biblioteki i jak go zbudować, spróbujemy dowiedzieć się jak ten proces wygląda. Na początek ustalmy jedną istotną rzecz – twórcy Mavena założyli, że z jednego projektu można zbudować jeden plik (pewną odmianą tej zasady są projekty wielomodułowe, ale o nich opowiem w następnym numerze). Mając to w pamięci zastanówmy się co można zrobić z projektem. Po pierwsze możemy zbudować ze źródeł plik wynikowy, na pewno też powinniśmy móc wyczyścić katalog roboczy przed kolejną próbą zbudowania projektu, na przykład po wprowadzeniu zmian w kodzie. Dodam, że w Mavenie dostrzeżona została również potrzeba tworzenia dokumentacji (nie tylko API) dla projektu, i ta potrzeba została opisana jako trzecia możliwość. Każda z nich, czyli budowanie, czyszczenie katalogu roboczego projektu oraz tworzenie dokumentacji zostały nazwane cyklami życia projektu (ang. build lifecycle). Te trzy opisane cykle są podstawowymi dostępnymi w Mavenie. Każdy z takich cykli składa się oczywiście z mniejszych części zwanych fazami (ang. phase).
Jeśli dobrze przyglądaliście się wynikom dotychczasowej pracy i jej przebiegowi zwróciliście zapewne uwagę na charakterystyczne komunikaty Mavena takie jak task-segment: [package], [compiler:compile] itp. Są to - w terminologii Mavena - fazy budowania projektu. Żeby w pełni je zrozumieć, należy je rozpatrywać w kontekście cykli budowy i celów. Aby problem skomplikować wspomnę jeszcze, że należy także pamiętać o typie projektu (znacznik packaging z pliku pom.xml). Brzmi to wszystko dość tajemniczo, ale przecież każdy zgodzi się, że źródła projektu zanim zamienią się w gotowy plik jar (lub inny) przechodzą pewne fazy. I właśnie te kilka etapów, które doprowadzają do gotowego produktu, połączone razem są cyklem. Każdy z etapów to oczywiście faza, a ich ilość i rodzaj zależny jest od projektu, nad którym pracujemy.
Zacznijmy więc od początku. Twórcy Mavena przewidzieli trzy różne cykle pracy z projektem. Pierwszy to cykl budowy, składający się z faz, które po kolei uruchomione na końcu pozostawią po sobie wynikowy plik – jaki to plik to zależy od typu projektu. Drugi cykl to tworzenie dokumentacji w postaci nadającej się do publikacji w sieci www. Trzeci cykl to czyszczenie katalogu roboczego po pakowaniu lub tworzeniu strony.
Dla przykładu zastanówmy się co trzeba zrobić, żeby z kilkunastu plików źródłowych javy otrzymać bibliotekę w postaci pliku jar. Pewnie oprócz kodu javowego mamy zestaw jakichś plików *.properties zawierających tłumaczenia komunikatów lub jakiegoś rodzaju konfigurację. Pliki te wymagają wstępnego przetworzenia. Nazwijmy tę fazę budowy process-resources. Potem oczywiście kompilujemy klasy – niech ta faza nazywa się compile. Kolejnym etapem jest oczywiście przygotowanie do testów, oczywiście również testy mogą wymagać przygotowania pewnych plików *.properties, więc kolejna faza to process-test-resources. Teraz warto oczywiście skompilować klasy zawierające kod testów – nazwijmy tę fazę test-compile. Kolejnym krokiem jest oczywiście wykonanie testów, czyli test. Jeśli nasz kod bezbłędnie przechodzi testy, możemy spakować klasy do pliku jar. I ta faza dostanie nazwę - a jakże! - package. Dwie kolejne rzeczy, które możemy zrobić z biblioteką, która została poprawnie zbudowana, to zainstalować ją w lokalnym repozytorium oraz zainstalować w repozytorium publicznym. Każda z tych czynności jest dla nas oddzielną fazą i nazwiemy je odpowiednio install oraz deploy. Podsumujmy teraz proces budowy biblioteki. Poniżej widzimy jak on przebiega.
process-resources
compile
process-test-resourcess
test-compile
test
package
install
deploy
Widoczne tutaj fazy tworzą kompletny cykl budowy pakietu wynikowego dla projektu typu jar. Aby rozwiać wszelkie wątpliwości, od razu wyjaśnię, że pakietem może być plik jar, aplikacja webowa w postaci pliku war, zestaw komponentów EJB w pliku jar, czy też archiwum EAR.
Skoro wiemy już czym jest cykl budowy i czym jest faza, to jesteśmy gotowi na poznanie kolejnego terminu – cel (ang. goal). Czym jest? Otóż cel to najmniejsze zadanie do wykonania w cyklu życia. Oczywiście takich zadań może przypadać na cykl więcej niż jedno i jest to dość częsta sytuacja. Domyślnie jednak sytuacja wygląda znacznie prościej – na jedną fazę przypada jeden cel z konkretnego pluginu.
Poniżej rozpisane są poszczególne fazy dla projektu typu jar wraz z informacją jaki plugin jest dla każdej z nich uruchamiany. Zaraz wyjaśnię też co z tej wiedzy dla nas wynika.
Faza/Plugin/Cel (goal)
process-resources/maven-resources-plugin/resources
compile/maven-compiler-plugin/compile
process-test-resources/maven-resources-plugin/testResources
test-compile/maven-compiler-plugin/testCompile
test/maven-surefire-plugin/test
package/maven-jar-plugin/jar
install/maven-install-plugin/install
deploy/maven-deploy-plugin/deploy
Każdy z tych pluginów podczas właściwej sobie fazy cyklu jest wykonywany z domyślną konfiguracją. Jednak może nam ona z rożnych powodów nie odpowiadać. Warto więc ją nieco zmienić. Zrobimy to troszkę angażując znowu nasz przykładowy projekt. Sięgnijmy do pliku App.java i zmieńmy go dodając w sekcji importów dwa wiersze:
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
i nieco dalej w klasie App kolejny wiersz ze zmienną statyczną do logowania:
private final static Log log = LogFactory.getLog(App.class);
i wewnątrz pętli tuż pod naszym dumnym „Hello Maven!” dość ekstrawagancką pętlę for w stylu Javy5:
for(String arg : args) {
log.info("arg => " + arg);
}
Teraz spróbujmy skompilować aplikację:
C:DevJaveExpressMavenHelloMaven>mvn package
… (pominięty wydruk)
[ERROR] BUILD FAILURE
[INFO] ------------------------------------------------------------------------
[INFO] Compilation failure
C:DevJaveExpressMavenHelloMavensrcmainjavacomjavaexpressApp.java:[16,23]
for-each loops are not supported in -source 1.3
(try -source 1.5 to enable for-each loops)
for(String arg : args) {
C:DevJaveExpressMavenHelloMavensrcmainjavacomjavaexpressApp.java:[16,23]
for-each loops are not supported in -source 1.3
(try -source 1.5 to enable for-each loops)
for(String arg : args) {
Od razu widać, że Maven zrozumiał o co nam chodzi, ale domyślna konfiguracja pluginu do przeprowadzania kompilacji zakłada, że kod jest zgodny z wersja 1.3 Javy (co nawet nie pozwala stosować wbudowanych asercji!). Należy więc skonfigurować moment kompilacji. Ale wciąż nie wiemy jak! Na stronie http://maven.apache.org/plugins/index.html znajduje się wykaz wbudowanych pluginów dostarczonych razem z Mavenen. Każdy z nich ma swoją stronę, na której można odnaleźć informacje o jego przeznaczeniu, działaniu, użyciu i konfiguracji – czyli wszystko czego nam potrzeba. Odnajdźmy więc plugin compiler. Na głównej stronie mamy już taką dawkę informacji, która na pewno rozwieje wszystkie nasze wątpliwości związane z tym pluginem. W części Goals Overview znajduje się informacja (podana w tabeli nr 1) o tym, który cel (ang. goal) kiedy jest uruchamiany. Teraz bardziej zainteresuje nas cześć Usage. Tam właśnie znajduje się instrukcja, według której należy plugin skonfigurować. Pełne możliwości konfiguracji dostępne są po wybraniu w lewej części menu Goals, a potem z listy compiler:compile (plugin:goal).
Wróćmy więc do naszego pliku pom.xml. Tuż za całą sekcją
<dependencies>
…
</dependencies>
tworzymy nową (build) i wprowadzamy to co widać na poniższym wydruku:
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.0</version>
<configuration>
<source>1.5</source>
<target>1.5</target>
</configuration>
</plugin>
</plugins>
</build>
Cały powyższy fragment jest dla nas nowy, ale najbardziej interesujące są wyróżnione części. Po pierwsze widać, że wszystkie pluginy są takimi samymi artefaktami jak pozostałe zależności projektu i dzięki zachowaniu tej samej hierarchii i zasady nazewnictwa możemy łatwo zorientować się do czego odnoszą się poszczególne fragmenty. Drugi wyróżniony fragment to część zawierająca konfigurację pluginu maven-compile-plugin. Wskazujemy jasno jaki poziom zgodności źródeł i klasy nas interesuje. Spróbujmy teraz zbudować projekt. Wśród wierszy, które odnajdziemy na ekranie terminala znajdzie się również taki:
[INFO] BUILD SUCCESSFUL
co znaczy, że tym razem Maven doskonale zrozumiał nasze intencje. Skoro udało się zbudować projekt (możemy to sprawdzić testując obecność pliku jar w katalogu target/), to czas na kilka kolejnych porcji informacji.
Idąc tym tropem możemy skonfigurować każdy dostępny plugin i użyć go w naszym projekcie. Zbliżając się ku końcowi tej części opowiem jeszcze, gdzie należy szukać informacji o fazach w cyklach projektu. Według mnie najlepszym miejscem i – wbrew pozorom – najłatwiejszym do odczytania i nie pozostawiającym żadnych wątpliwości, są źródła Mavena. W drzewie kodu znajduje się plik maven-core/src/main/resources/META-INF/plexus/components.xml, opisujący dokładnie wszystkie cykle dla wbudowanych celów, na przykład wspomniany jar-lifecycle. Ciekawy jest cykl clean. Widać, że składa się z trzech faz,
pre-clean
clean
post-clean
ale tylko jedna jest w domyślnej konfiguracji wykorzystywana. Sprawdźmy czy rzeczywiście tak właśnie jest. Zaglądamy do katalogu naszego projektu i wykonujemy poniższe polecenie:
C:DevJaveExpressMavenHelloMaven>mvn clean
[INFO] Scanning for projects...
[INFO] ------------------------------------------------------------------------
[INFO] Building HelloMaven
[INFO] task-segment: [clean]
[INFO] ------------------------------------------------------------------------
[INFO] [clean:clean]
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESSFUL
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 1 second
[INFO] Finished at: Wed Oct 29 23:55:40 CET 2008
[INFO] Final Memory: 3M/5M
[INFO] ------------------------------------------------------------------------
Na powyższym wydruku widać, że zażądaliśmy wykonania cyklu clean. Ale z trzech wymienionych faz widać tylko jedną i uruchomiony skonfigurowany dla niej plugin. Co z pozostałymi dwoma? No cóż, pozostają do naszej dyspozycji. Możemy samodzielnie uruchomić wykonanie jakiejś czynności poprzez odpowiednią konfigurację. Poniżej przykładowe uruchomienie zadania Anta w pierwszej fazie cyklu clean:
...
<plugin>
<artifactId>maven-antrun-plugin</artifactId>
<executions>
<execution>
<phase>pre-clean</phase>
<configuration>
<tasks>
<echo>"Ant uruchomiony w Mavenie :)"</echo>
</tasks>
</configuration>
<goals>
<goal>run</goal>
</goals>
</execution>
</executions>
</plugin>
…
Oczywiście powyższe linie należy dodać do naszego roboczego pliku pom.xml, np. tuż za konfiguracją pluginu do kompilacji projektu. Gdy wykonamy w katalogu projektu mvn clean, w konsoli pojawi się spodziewany komunikat:
C:DevJaveExpressMavenHelloMaven>mvn clean
…
[INFO] Building HelloMaven
[INFO] task-segment: [clean]
[INFO] ------------------------------------------------------------------------
[INFO] [antrun:run {execution: default}]
[INFO] Executing tasks
[echo] "Ant uruchomiony w Mavenie :)"
[INFO] Executed tasks
[INFO] [clean:clean]
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESSFUL
[INFO] ------------------------------------------------------------------------
...
czyli, dokładnie to czego się spodziewaliśmy. W podobny sposób możemy konfigurować dodatkowe czynności podczas każdej fazy dowolnego cyklu życia, możemy także zamieniać domyślnie skonfigurowane pluginy swoimi własnymi. Na tym właśnie polega ogromna elastyczność Mavena. W domyślnej konfiguracji jest niezwykle przydatny, jednak skrzydła rozwija dopiero, gdy dodamy do niego szczyptę fantazji.
Kilka słów więcej o magii pliku pom.xml
Nie można pisać o zarządzaniu procesem budowania projektu za pomocą Mavena, nie opisując pliku pom.xml. To, że plik ten pełni kluczową rolę to już na pewno zauważyliście. Jego minimalną postać również – pojawia się ona po utworzeniu projektu. Ale na tym nie kończą się, ani jego możliwości, ani rola. Podsumowując tę część postaram się w miarę dokładnie (ale bez przesady, gdyż wiedzę tę będziemy rozwijać w kolejnych częściach cyklu o Mavenie) zapoznać Was ze strukturą pliku, oraz jego rolą w dystrybucji informacji o projekcie (zarówno podczas tworzenia dokumentacji jak i podczas wyszukiwania artefaktów za pomocą wspomnianych już narzędzi).
Spróbujmy podzielić cały plik na kilka części (jednak nieco inaczej niż w podręczniku dostępnym na stronach http://maven.apache.org/) zbierając elementy konfiguracji według ich przeznaczenia. Najpierw elementy identyfikujące projekt:
- groupId – informuje o grupie produktów, w której znajduje się projekt, zwykle (choć nie zawsze) składa się - na podobieństwo javowych pakietów - z domeny, dostawcy oraz nazwy całej grupy produktów,
- artifactId – to bezpośrednia nazwa projektu w obrębie grupy, np. crm-api, dao-jdbc itp. (patrz uwaga wyżej),
- version – określenie numeru wersji, za pomocą liczb lub liczb mieszanych z opisem, np. 1.0, 2.1, 2.2-BETA, 2.2-RC1, itp. (wersjom przyjrzymy się dokładnie w kolejnym numerze),
- packaging – sposób pakowania projektu, który jednocześnie określa także fazy cyklu budowy dla projektu (inne nieco dla różnego rodzaju projektów).
Kolejną grupą będą elementy opisujące projekt, dostawcę oraz twórców:
- name – nazwa dla projektu, nieco bardziej opisowa niż zbitek składający się z grupId oraz artifactId, nazwa ta będzie używana w kilku miejscach, warto wybrać taką, która będzie kojarzyć się z projektem, ale nie będzie długa, np. SuperCRM.API – dla klasa i interfejsów stanowiących API projektu,
- description – opis projektu, może być dowolnie długi, ale warto zachować umiar, gdyż jeśli do wyszukiwania artefaktów będących wynikiem naszej pracy będziemy używać wyszukiwarki podobnej do opisanej na początku artykułu (oczywiście przeszukującej nasze firmowe lub prywatne repozytorium) to zawartość sekcji description pojawi się w wynikach wyszukiwania,
- url – tutaj można umieścić adres witryny przechowującej informacje o projekcie, (adres w wersji pełnej np. http://dev.supercrm.com/ lub http://supercrm.com,
- organization – element zbiorczy zawierający nazwę i adres strony domowej (zwyczajowo) organizacji zajmującej się rozwijaniem projektu, czyli – w przypadku klasycznej działalności komercyjnej - po prostu firmy, która zajmuje się jego tworzeniem; składa się z dwóch zagnieżdżonych elementów:
- name – nazwa organizacji,
- url – adres strony domowej organizacji,
- inceptionYear – rok rozpoczęcia prac nad projektem, wartość ta zostanie wykorzystana w notce o prawach autorskich w dokumentacji generowanej przez Mavena,
- licenses – licencje na rozwijany produkt (może być ich oczywiście więcej niż jedna), każdą licencję podajemy w oddzielnym elemencie <licence></licence>,
- developers – podobnie jak w przypadku licencji, jest to element zbiorczy, zawierający jeden lub więcej elementów developer, z których każdych składa się z następujących elementów:
- id – identyfikator developera, pozwalający np. powiązać go z informacjami o zmianach w systemie kontroli wersji bądź systemie zgłaszania błędów itp.,
- name – imię i nazwisko (lub pseudonim) developera,
- email – sprawa wydaje się oczywista :),
- organization – jeśli developer pracujący nad projektem na stałe zatrudniony jest (w przypadku działalności komercyjnej) lub związany (w przypadku działalności non profit) z organizacją inną niż rozwijając produkt, to można podać tu jej nazwę,
- organizationUrl – j.w., ale zawieraj informacje o stronie domowej macierzystej organizacji develepera,
- roles – element zbiorczy zawierający pojedyncze elementy role informujące o roli developera w projekcie (np. jee-developer, architect, webmaster, itp.),
- contributors – informacje podobne jak te zawarte w elemencie developers, tutaj jednak znajdują się z założenia informacje o osobach zgłaszających błędy (nie uczestniczące w samym procesie wytwarzania jako dostawcy kodu), dane poszczególnych osób (dokładnie te same co w przypadku developerów) otaczane są elementem contributor.
Sporo już się dowiedzieliśmy o części informacyjnej pliku pom.xml, spróbujmy zamienić tę wiedzę na rzeczywiste korzyści. Otwórzmy więc ten opisujący nasz projekt i uzupełnijmy jak poniżej:
...
<name>HelloMaven</name>
<url>http://javaexpress.pl/hellomaven</url>
<description>
Projekt przykładowy. Pomaga zrozumieć działanie Mavena.
</description>
<organization>
<name>JaveExpress</name>
<url>http://javaexpress.pl</url>
</organization>
<inceptionYear>2008</inceptionYear>
<licences>
<licence>
<name>Apache 2</name>
<url>http://www.apache.org/licenses/LICENSE-2.0.txt</url>
<distribution>repo</distribution>
<comments>Ulubiona licencja organizacji</comments>
</licence>
</licences>
<developers>
<developer>
<id>jjhop</id>
<name>Rafal Kotusiewicz</name>
<email>r.kotusiewicz@javaexpress.pl</email>
<url>http://javaexpress.pl/author/jjhop/</url>
<organization>JavaExpress</organization>
<organizationUrl>http://javaexpress.pl</organizationUrl>
<roles>
<role>architect</role>
<role>developer</role>
</roles>
<timezone>-1</timezone>
<properties>
<picUrl>http://javaexpress.pl/author/jjhop/mini.png</picUrl>
</properties>
</developer>
</developers>
<contributors>
<contributor>
<!-- tutaj odpowiednie dane -->
</contributor>
</contributors>
<dependencies>
...
Kolejna grupa jest dość szeroka, łączy bowiem informacje o tym, gdzie szukać brakujących zależności, jeśli nie ma ich w lokalnym repozytorium (*repositories) z informacjami porządkującymi dane projektu. Zaczniemy od konfiguracji repozytoriów, w których Maven będzie szukał brakujących artefaktów. Składają się na nią dwa elementy głównej konfiguracji wraz z elementami podrzędnymi:
- repositories – repozytoria, w których Maven będzie szukał głównych zależności projektu, czyli tych wymienionych wewnątrz elementu dependencies, są to jednocześnie repozytoria, do których w razie potrzeby może „wysłać” efekt naszej pracy (o tym więcej w przyszłości),
- pluginRepositories – to dodatkowe repozytoria, w których będą poszukiwane dodatkowe pluginy służące np. do specjalnego sposobu budowania (pakowania) projektu, do szczególnego typu raportowania itp...
Każdy z tych elementów zawiera elementy podrzędne – odpowiednio repository i pluginRepository – składające się z informacji pozwalających zidentyfikować repozytorium oraz „zajrzeć” do jego zawartości. Wspomniane informacje to:
- id – identyfikacja repozytorium, jeśli jest chwilowo niedostępne, to dzięki temu identyfikatorowi Maven przez jakiś czas nie będzie próbował nawiązać z nim połączenia,
- name – przyjazna nazwa repozytorium pojawiająca się podczas logowania informacji o przebiegu procesu budowania (lub któregoś z dwóch pozostałych) projektu,
- url – pełen adres repozytorium (razem z protokołem), najczęściej w stylu http://repo.xxx.org/maven2, ale może także zaczynać się od ftp://.
Bardziej szczegółowa konfiguracja repozytoriów zostanie opisana w kolejnych częściach wraz z odpowiednimi przykładami tak, aby nie zakłócać normalnego toku poznawczego :). Cztery kolejne elementy informacyjne to:
- issueManagement – wskazuje system zarządzania błędami i potrzebami tworzonego oprogramowania, element składa się z dwóch podrzędnych (patrz → przykład użycia w naszym projekcie),
- ciManagement – konfiguracja systemu CI (ang. continuous integration) obsługującego projekt (np. Continuum – najchętniej wykorzystywany wraz z Mavenem, Cruise Control), główny element zawiera elementy podrzędne zawierające dokładne informacje (patrz → przykład użycia w naszym projekcie).
- mailingLists – informacje o listach mailingowych związanych z projektem, główny zawiera elementy podrzędne opisujące konfigurację poszczególnych list, z których każda zawieraj następujące dane:
- name – nazwa listy wysyłkowej,
- subscribe – adres email, pod który należy wysłać wiadomość, aby zapisać się na listę,
- unscubscribe – j.w., ale z odwrotnym efektem,
- post – adres email, na który wysyła się wiadomości na listę,
- archive – URL wskazujący archiwum listy dostępne przez www (jeśli istnieje taka możliwość),
- otherArchives – zbiór pojedynczych elementów otherArchive zawierających informacje tożsame z tymi z elementu archive,
- scm - informacje o systemie kontroli wersji, w którym przechowywane są źródła oraz inne pliki projektu (patrz → przykład użycia w naszym projekcie).
Kolejnym ważnym elementem jest distributionManagement, którego zadaniem jest precyzyjne opisanie sposobu (oraz statusu) dystrybucji artefaktów będących wynikiem budowy projektu, a także adresy repozytoriów, w których będą instalowane. Także tutaj podajemy sposób i miejsce, w którym umieszczona będzie strona informacyjna projektu (to jak ją stworzyć będzie ostatnim elementem tej części artykułu) – mam oczywiście na myśli raport o stanie projektu w wersji html.
W wypadku tego elementu, na razie nie będziemy posługiwać się przykładem i wrócimy do niego w jednej z kolejnej części artykułu, gdy zajmiemy się zarządzaniem procesem budowy.
Ostatnią częścią opisującą magię pliku pom.xml będzie dość dokładna konfiguracja budowania projektu. Proces budowania opisany jest – a jakże! - w ramach elementu o nazwie build. Tak naprawdę, to domyślna konfiguracja jest dość dobra. Większość domyślnych wartości można zaaprobować bez żadnych zmian, czasami jednak trzeba coś zmienić. Wtedy właśnie do akcji wkracza konfiguracja w obrębie elementu build. Trzy poniższe elementy wydają się dobrym przykładem na początek:
- finalName – tutaj możemy zdefiniować własną wartość dla nazwy pliku wynikowego (np. supercrm.war zamiast supercrm-1.0-SNAPSHOT.war),
- defaultGoal – domyślny cel procesu budowania, jeśli zdefiniujemy go tutaj, nie będzie trzeba podawać go w wierszu poleceń, oczywiście, jeśli mimo zdefiniowania go, wywołamy Mavena z inną wartością to właśnie ona zostanie wzięta pod uwagę,
- directory – katalog, w którym będą przechowywany wszystkie wyniki – także pośrednie – procesu budowania (domyślnie ma wartość ${basedir}/target, przy czym ${basedir} to katalog projektu),
- sourceDirectory – katalog, zawierający pliki źródłowe (*.java) projektu,
- testSourceDirectory – katalog, w którym znajdują się pliki źródłowe (*.java) zawierające testy,
- outputDirectory – katalog, do którego trafią skompilowane klasy projektu,
- testOutputDirectory – katalog, do którego trafią skompilowane klasy testowe.
Kolejnym ważnym elementem, który tu możemy skonfigurować są katalogi z zasobami projektu. Pamiętamy, że domyślnie takim miejscem jest katalog ${basedir}/src/main/resources (oraz ${basedir}/src/test/resources), czasami zachodzi jednak potrzeba wskazania więcej niż jednego katalogu, jeśli z jakichś powodów chcemy np. rozdzielić różne ich rodzaje. Katalogi zasobów głównych obejmujemy elementem zbiorczym resources, katalogi dla procesu testowania elementem testResources. W każdym z nich możemy zdefiniować jeden lub więcej elementów resource o następującej strukturze:
- directory – wskazuje katalog zawierający interesujące nas zasoby,
- targetPath – katalog, do którego po przetworzeniu trafią zasoby z directory,
- filtering – (true lub false) informacja o tym, czy pliki zasobów mają podlegać przetwarzaniu przez mechanizm podstawiania zmiennych,
- includes – zawiera jeden lub więcej elementów include wskazujących wprost lub za pomocą znaków wieloznacznych, które elementy z katalogu directory mają podlegać przetworzeniu i włączeniu do wyników procesu budowania,
- excludes – jw. lecz zawiera elementy exclude i dotyczy wyłączenia z procesu budowania.
Poniżej przykładowa konfiguracja zawierająca wspomniane elementy:
...
<build>
<defaultGoal>install</defaultGoal>
<directory>${basedir}/target</directory>
<finalName>supercrm.war</finalName>
<sourceDirectory>${basedir}/src/main/java</sourceDirectory>
<testSourceDirectory>${basedir}/src/test/java</testSourceDirectory>
<outputDirectory>${basedir}/target/classes</outputDirectory>
<testOutputDirectory>${basedir}/target/test-classes</testOutputDirectory>
<resources>
<resource>
<directory>${basedir}/src/main/psd_images</directory>
<targetPath>img</targetPath>
<filtering>false</filtering>
<includes>
<include>**/*.jpg</include>
</includes>
<excludes>
<exclude>**/*.psd</exclude>
</excludes>
</resource>
</resources>
...
</build>
…
Kolejną rzeczą, którą chcemy konfigurować w tym miejscu, to oczywiście pluginy, które obsługują proces budowania. Wspominałem już dość szeroko o powiązaniu konkretnych pluginów z fazami budowy projektu, wspominałem także o tym, że można je konfigurować (oczywiście zakres i rodzaj konfiguracji zależy od konkretnych pluginów). Widzieliśmy już, że można konfigurując plugin obsługujący kompilację wskazać mu poziom zgodności źródeł (czasami wręcz nie można się bez tej możliwości obyć). Można także konfigurować inne jego opcje (np. kodowanie znaków w kodzie źródłowym), a także różnego rodzaju zachowanie innych pluginów. Do tego celu został przewidziany element plugins w build. Zawiera jeden lub więcej elementów plugin, z których każdy oprócz elementów identyfikujących (groupId, artifactId, version) zawiera inne sterujące jego działaniem. Oto one:
- extensions – (true lub false) informuje o tym czy plugin jest rozszerzeniem Mavena czy też nie (w jednej z kolejnej części opiszę, jak zbudować własny typ projektu, jak np. jar lub war, wtedy też użyjemy w tym miejscu wartości true, poza tym rzadko tu zmienia się wartość domyślną, która jest oczywiście false),
- inherited - (true lub false) ma zastosowanie tylko w przypadku projektów wielomodułowych (o których opowiem w kolejnym odcinku), decyduje o tym czy konfiguracja jest dziedziczona przez moduły (konkretnie przez pliki pom.xml w poszczególnych modułach,
- configuration – zestaw elementów, których nazwy określają rodzaj konfiguracji o zawartość jej wartość (np. <encoding>utf-8 </encoding> - encoding jest zmienną konfiguracyjną, a utf-8 jest wartością, coś na kształt encoding=utf-8), elementów może być wiele i w zależności od modułu mogą być zagnieżdżone,
- dependencies – zależności modułu, rzadko wykorzystywana, chyba, że uruchamiamy jakieś zadanie ant'a, które potrzebuje dodatkowych bibliotek, ponad te, które dostarczane są z Antem,
- executions – każdy plugin może być uruchomiony podczas więcej niż jednej faz i może zostać wykonany więcej niż jeden jego cel (ang. goal), można więc skonfigurować każde wykonanie oddzielnie; element ten zawiera jeden lub więcej elementów execution.
Tym razem to już wszystko o konfiguracji w elemencie build. Przykład nieco uproszczony pojawił się już w tym artykule, więc wydaje się, że nie warto go powtarzać. Więcej pojawi się jednak z czasem, kiedy będziemy rozbudowywać nasz projekt w trakcie poznawania Mavena. Teraz czas na ostatnią część artykułu poświęconą tworzeniu strony informacyjnej projektu.
Wizytówka projektu, czyli www w minutę
Na sam koniec zostawiłem coś, co niezwykle podoba mi się, gdy korzystam z Mavena. Otóż, gdy projekt rozwija się (nieważne czy jest to projekt komercyjny czy opensource) nadchodzi taki moment, że należy pewne informacje dotyczące go umieszczać w ogólnie dostępnym miejscu – najczęściej jest to sieć www (być może firmowy intranet). Zespół pracujący nad rozwojem oprogramowania pragnie podzielić się swoimi osiągnięciami, czasami po prostu potrzeba raportów na temat jakości kodu podanych w przystępnej formie. Powodów tworzenia stron tego typu jest wiele. A co z tym wspólnego ma Maven? Jednym z trzech cykli budowy projektu jest właśnie tworzenie jego dokumentacji do postaci plików html – myślę oczywiście o cyklu site.
Zaglądamy więc do katalogu projektu i próbujemy to w następujący sposób:
C:DevJaveExpressMavenHelloMaven>mvn site
[INFO] Scanning for projects...
[INFO] ------------------------------------------------------------------------
[INFO] Building HelloMaven
[INFO] task-segment: [site]
[INFO] ------------------------------------------------------------------------
…
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESSFUL
[INFO] ------------------------------------------------------------------------
…
Po chwili w katalogu target/site pojawi się mnóstwo plików *.html a wśród nich index.html. Właśnie od niego zacznijmy. Otwórzcie go w przeglądarce, powinien wyglądać mniej więcej tak jak widać to na rysunku.
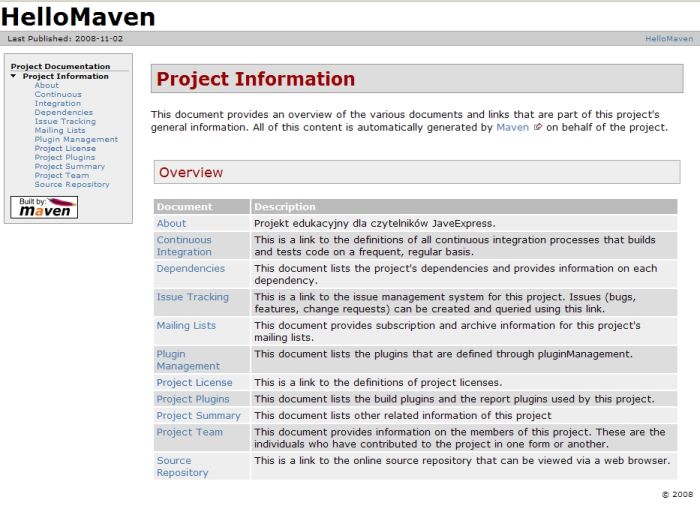
Rysunek 1. Strona projektu wygenerowana przez Maven2
Przyglądając się stronie zauważycie znajome informacje, począwszy od tych dotyczących ogólnych informacji o projekcie (element description z pliku pom.xml), które pojawiają się tu w części About poprzez wszystkie dane konfiguracyjne, jak adres repozytorium, adres systemu kontroli wersji czy adresy list wysyłkowych związanych z projektem, aż po skład zespołu rozwijającego projekt. Zachęcam do przejrzenia tego co wynika wprost z najprostszego zastosowania cyklu site i zmierzenia się z kolejną porcją możliwości skonfigurowania Mavena według własnych potrzeb. Sprawdźmy zatem, co możemy jeszcze zrobić w kwestii strony informacyjnej projektu. Obsługę cyklu site konfigurujemy w obrębie elementu reporting, który jest elementem równorzędnym do build i innych. W jego obrębie możemy skonfigurować:
- outputDirectory – katalog, w którym znajdzie się wygenerowana strona,
- plugins – kolekcja pluginów (w postaci elementów plugin), które zostaną uruchomione podczas tworzenia dokumentacji, są to pluginy generujące różnego rodzaju raporty o projekcie.
Kilka przydatnych pluginów jest dostępnych w repozytoriach Mavena. Ich opis oraz konfigurację możemy znaleźć po adresem http://maven.apache.org/plugins/index.html w sekcji Reporting plugins. Ich wykorzystanie jest niezwykle proste. Wystarczy umieścić dane identyfikacyjne wybranego pluginu w obrębie elementu plugins.
…
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-changelog-plugin</artifactId>
</plugin>
</plugins>
…
Korzystając z linków na wspomnianej stronie i dokumentacji dołączonej do każdego pluginu, można dostosować konfigurację do własnych potrzeb. Nie będziemy teraz opisywać szczegółów, myślę, że każdy z Was uzbrojony w informacje zawarte w artykule chętnie samodzielnie poeksperymentuje z raportami.
Obiecuję, że przy okazji kolejnego spotkania pokażę jak skonfigurować projekt tak, by maksymalnie skorzystać z możliwości, jakie daje automatyczne tworzenie dokumentacji projektu.
Co w kolejnej części?
Kolejna część (czyli już w marcu) wprowadzi nas w tajniki składania projektu z kilku części. Zobaczymy jak korzystać z Mavena w naszych ulubionych środowiskach – Netbeans, IntelliJ Idea oraz Eclipse. Podłączymy nasz projekt do repozytorium, systemu śledzenia błędów oraz systemu CI (skorzystamy oczywiście z Continuum). Rozbudujemy także nieco stronę projektu. I przede wszystkim – mam nadzieję – będziemy się dobrze bawić!
Source: http://www.javaexpress.pl/article/show/Maven_2__jak_ulatwic_sobie_prace_cz_I