 Published on JAVA exPress
(http://www.javaexpress.pl)
Published on JAVA exPress
(http://www.javaexpress.pl)
Spring - kontener wstrzykiwania zależności
Marcin Świerczyński
Issue 7 (2010-03-30)
Czym jest Spring?
Spring Framework jest to platforma, której głównym celem jest uproszczenie procesu tworzenia oprogramowania klasy enterprise w technologii Java/J2EE. Rdzeniem Springa jest kontener wstrzykiwania zależności, który zarządza komponentami i ich zależnościami. Umożliwia on automatyczne wykrywanie tych zależności bez większego udziału programisty. Nie ma także problemu z własnoręczną konfiguracją – jeśli taki sposób pracy bardziej nam odpowiada. Cel jest jednak jeden – zmniejszenie stopnia związania klas. Artykuł ten ma za zadanie zaprezentować Springa właśnie w tym kontekście. Ale o tym za chwilę – najpierw kilka słów o architekturze frameworka.
Architektura Spring Framework
Spring jest rozwiązaniem modułowym. Bez problemu możemy wykorzystać jedynie te części, których potrzebujemy. W skrócie omówię niektóre z nich.
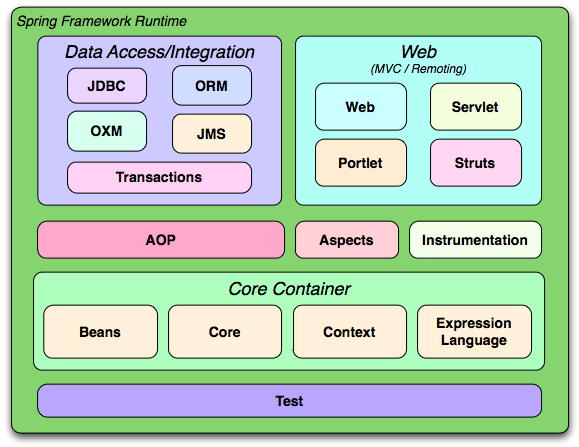
Rysunek 1: Architektura Spring Framework, źródło: Spring Framework Reference
Core Container
Core i Beans – podstawowe moduły, zawierają funkcjonalność Inversion of Control i Dependency Injection, będące tematem przewodnim niniejszego artykułu. To dzięki nim możliwe jest oddzielenie konfiguracji i specyfikacji zależności od logiki biznesowej.
Context – zapewnia dostęp do obiektów na poziomie frameworka w sposób analogiczny do JNDI. Dodaje wsparcie dla internacjonalizacji i propagowania zdarzeń, a także EJB i JMX.
DAO
DAO zapewnia wsparcie dla metod utrwalnia obiektów, w szczególności JDBC, ORM, OXM (mapowanie XML), JMS (tworzenie i przetwarzanie wiadomości). Dostarcza gotową do wykorzystania pulę połączeń, a także możliwość deklaratywnego definiowania transakcji. Pozwala na łatwe mapowanie ResultSetów na listę obiektów klas domenowych.
Web
Web zawiera własny framework webowy – Spring Web MVC. Pozwala także wykorzystywać inne technologie, np. Struts, JSF, Velocity. Wspomaga proces ładowania plików na serwer.
AOP
AOP wspiera programowanie zorientowane aspektowo zarówno w wydaniu prostszym (Spring AOP), jak i bardziej rozbudowanym (AspectJ).
Test
Test zawiera mechanizmy służące do testowania aplikacji (JUnit lub TestNG). W szczególności dostarcza mocków.
O wstrzykiwaniu zależności
Zrozumienie celowości Dependency Injection i Inversion of Control często stanowi problem dla początkujących programistów. Spróbujmy zatem omówić to na przykładzie.
Wady ścisłego wiązania klas
Na początku uczyliśmy się, że obiektowe języki programowania pozwalają na modelowanie otaczającego nas świata. To prawda, ale niestety obiekty domenowe nie są zbyt użyteczne bez otaczającego je kontekstu. Rozważmy związek pomiędzy obiektem dostępu do danych (DAO), a obiektem klasy DataSource, reprezentującym bazę danych. Oczywiście obiekt DAO zależy od bazy danych. W klasycznym podejściu wyglądałoby to tak:
public class JdbcBookDao implements BookDao {
private BasicDataSource dataSource;
public JdbcBookDao() {
dataSource = new BasicDataSource();
dataSource.setDriverClassName("com.mysql.jdbc.Driver");
dataSource.setUrl("jdbc:mysql://localhost/javaexpress?autoReconnect=true");
dataSource.setUsername("username");
dataSource.setPassword("password");
}
// ...inne metody
}
Sposobem na wyeliminowanie zależności z klasy
jest stworzenie zależności poza klasą
i wstrzyknięcie jej do środka.
Problemem, który pierwszy rzuca się w oczy jest tutaj zaszycie parametrów dostępu do bazy danych w kodzie. Można to rozwiązać poprzez wykorzystanie klasy java.util.Properties, ale to dopiero początek. Kolejną bolączką jest uzależnienie się od konkretnej implementacji (org.apache.commons.dbcp.BasicDataSource), co wpływa ujemnie na elastyczność rozwiązania. Zwróćmy uwagę, że posługiwanie się samym interfejsem niczego nie zmieni, ponieważ do użycia przedstawionych metody potrzebujemy konkretnej klasy.
Wstrzykiwanie zależności
Sposobem na wyeliminowanie konkretnej zależności z klasy JdbcBookDao jest stworzenie zależności poza klasą i wstrzyknięcie jej do środka. To zapewnia większą elastyczność, ponieważ konfigurację możemy modyfikować nie naruszając klasy, która z niej korzysta. Nie dość, że minimalizujemy w ten sposób ryzyko powstania błędu, to unikamy konieczności modyfikacji bytu, do którego źródeł nie musimy mieć przecież dostępu! W kodzie wyglądałoby to tak:
public class JdbcBookDao implements BookDao {
private DataSource dataSource;
public void setDataSource(DataSource dataSource) {
this.dataSource = dataSource;
}
// ...inne metody
}
Teraz obiekt DAO nie jest ściśle związany z żadną klasą, co jest na pewno krokiem naprzód, ale w tym momencie tylko przenieśliśmy konstrukcje obiektu wyżej, do klienta:
public class BookService {
private JdbcBookDao bookDao;
public BookService() {
try {
Properties props = new Properties();
props.load(new FileInputStream("dataSource.properties"));
BasicDataSource dataSource = new BasicDataSource();
dataSource.setDriverClassName(props.getProperty("driverClassName"));
dataSource.setUrl(props.getProperty("url"));
dataSource.setUsername(props.getProperty("username"));
dataSource.setPassword(props.getProperty("password"));
bookDao = new JdbcBookDao();
bookDao.setDataSource(dataSource);
} catch (IOException e) {
e.printStackTrace();
}
}
}
Teraz obiekt DAO nie jest ściśle związany z żadną klasą,
co jest na pewno krokiem naprzód
Co gorsza, w ten sposób stworzyliśmy zależność między BookService, a dwoma klasami konkretnymi: BasicDataSource oraz JdbcBookDao, co właściwie oznacza początek do punktu wyjścia. Na szczęście nie oznacza to, że nasze eksperymenty poprowadziły nas w złym kierunku. Teraz musimy tylko przenieść proces wstrzykiwania do zakresu odpowiedzialności innego bytu.
Inversion of Control
W tradycyjnym programowaniu, to w zakresie odpowiedzialności klienta jest pobieranie wymaganych przez niego komponentów. W przypadku IoC, kontener zajmuje się procesem wstrzykiwania zależności. Klient prosi tylko o pewien byt, ale to kontener decyduje jak i kiedy go dostarczyć. Jak ma się to naszego przykładu?
Otóż klient nie musi bezpośrednio inicjalizować obiektu klasy JdbcBookDao. Zamiast tego, odpowiedni obiekt jest wstrzykiwany do klasy BookService.
public class BookService {
private BookDao bookDao;
public void setBookDao(BookDao bookDao) {
this.bookDao = bookDao;
}
}
A gdzie kończy się łańcuch zależności? W pliku konfiguracyjnym Springa:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd">
<bean id="dataSource" class="org.apache.commons.dbcp.BasicDataSource"
destroy-method="close"> <!-- (1) -->
<property name="driverClassName" value="com.mysql.jdbc.Driver" />
<property name="url"
value="jdbc:mysql://localhost/javaexpress?autoReconnect=true" />
<property name="username" value="username" />
<property name="password" value="password" />
</bean>
<bean id="bookDao" class="dao.JdbcBookDao"> <!-- (2) -->
<property name="dataSource" ref="dataSource" />
</bean>
<bean id="bookService" class="service.BookService"> <!-- (3) -->
<property name="bookDao" ref="bookDao" />
</bean>
</beans>
Najważniejsze jest to, iż cała konfiguracja
jest w pełni transparentna do klasy usługi,
co zapewnia luźnie wiązanie klas.
W miejscu oznaczonym przez (1) definiujemy źródło danych. Na uwagę zasługuje tu atrybut destroy-method, w którym podajemy nazwę metody, która zostanie wywołana w chwili usuwania obiektu DataSource. W (2) deklarujemy obiekt klasy JdbcBookDao. Jak pamiętamy, klasa ta ma jedno pole – dataSource – oraz publiczny setter je ustawiający. Dzięki nim możliwe jest wstrzyknięcie uprzednio określonego źródła danych do obiektu. Powiązanie między beanem DataSource oraz JdbcBookDao zapewnia ten sama fraza będąca odpowiednio identyfikatorem komponentu i wartością atrybutu ref własności dataSource. Analogiczna procedura zachodzi w (3).
W tym momencie łańcuch zależności został zakończony i wszystkie niezbędne obiekty dostarczone do klasy BookService. Najważniejsze jest to, iż cała konfiguracja jest w pełni transparentna do klasy usługi, co zapewnia luźnie wiązanie klas.
Przejdźmy teraz do konkretnej implementacji i stwórzmy w pełni działający przykład.
IoC w Springu – podstawy
Nasza aplikacja będzie bardzo prostą implementacją narzędzia do obsługi domowej biblioteczki. Pozycje, które posiadamy na półce są zapisane w pliku o odpowiednim formacie. W szczególności przechowywana jest tam data wypożyczenia książki. Zadaniem aplikacji będzie wyszukanie pozycji, które wypożyczyliśmy ponad 30 dni temu.
Tworzenie klasy domenowej
Aplikacja zawiera tylko jedną klasę domenową, reprezentującą książkę:
package model;
//... pominięto importy
public class Book {
private String title;
private String author;
private Date lendDate;
public Book(String title, String author, Date lendDate) {
this.title = title;
this.author = author;
this.lendDate = lendDate;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getAuthor() {
return author;
}
public void setAuthor(String author) {
this.author = author;
}
public Date getLendDate() {
return lendDate;
}
public void setLendDate(Date lendDate) {
this.lendDate = lendDate;
}
}
Jak wspomniano, nasze książki przechowywać będziemy w pliku CSV, np. takim:
Spring in Action,Craig Walls,20091028
Java Persistence with Hibernate,Christian Bauer,20091230
Spring in Practice,Willie Wheeler,20091127
Pierwsze pole to tytuł książki, drugie autor, a ostatnie – data wypożyczenia w formacie yyyyMMdd.
Tworzenie warstw DAO i usług
Kolejnym etapem jest konstrukcja interfejsu DAO. Będzie on zawierał tylko jedną metoda – wyciąganie wszystkich książek.
Powierzymy zadanie wstrzykiwania tej nazwy Springowi
package dao;
//... pominięto importy
public interface BookDao {
List<Book> findAll() throws Exception;
}
Teraz przyszła kolej na implementacje interfejsu w postaci klasy odczytującej dane z pliku. Istotne z naszego punktu widzenia jest założenie, że nazwa i ścieżka do tego pliku może się zmieniać, więc nie chcemy przechowywać jej na stałe w kodzie. Powierzymy zadanie wstrzykiwania tej nazwy Springowi.
package dao;
//... pominięto importy
public class CsvBookDao implements BookDao {
private String csvBooksFile;
public void setCsvBooksFile(String csvBooksFile) {
this.csvBooksFile = csvBooksFile;
}
@Override
public List<Book> findAll() throws Exception {
List<Book> booksList = new ArrayList<Book>();
DateFormat df = new SimpleDateFormat("yyyyMMdd");
BufferedReader br = new BufferedReader(new FileReader(csvBooksFile));
String line;
while ((line = br.readLine()) != null) {
String[] fields = line.split(",");
// pomijamy kwestie blednego formatu pliku
String title = fields[0];
String author = fields[1];
Date lendDate = df.parse(fields[2]);
Book book = new Book(title, author, lendDate);
booksList.add(book);
}
br.close();
return booksList;
}
}
Jak widzimy, klasa zawiera pole prywatne przechowujące ścieżkę do pliku. Ponadto stworzyliśmy publiczny mutator (setter), który aktualizuje wartość tego pola. Dzięki temu Spring może wstrzyknąć odpowiednią wartość z plików konfiguracyjnych.
Implementacja metody findAll() nie ma tak naprawdę wiele wspólnego z samym Springiem i polega na odczytywaniu kolejnych linii pliku, a następnie dzieleniu tych linii na części odpowiadające poszczególnym polom klasy Book.
Które rozwiązanie stosować?
To tak naprawdę kwestia gustu i wyczucia
Ostatnią niemal klasą, którą musimy zbudować jest klasa usługi – BookService. Jej zadaniem będzie wybranie tych książek spośród wszystkich w bazie, które pożyczyliśmy co najmniej 30 dni temu.
package service;
//... pominięto importy
public class BookService {
private BookDao bookDao;
public void setBookDao(BookDao bookDao) {
this.bookDao = bookDao;
}
public List<Book> findBooksLent30DaysAgo() throws Exception {
List<Book> booksLent30DaysAgo = new ArrayList<Book>();
List<Book> allBooks = bookDao.findAll();
Date thirtyDaysAgo = daysAgo(30);
for (Book book : allBooks) {
boolean bookWasLent30DaysAgo = book.getLendDate()
.compareTo(thirtyDaysAgo) <= 0;
if (bookWasLent30DaysAgo)
booksLent30DaysAgo.add(book);
}
return booksLent30DaysAgo;
}
private Date daysAgo(int days) {
GregorianCalendar gc = new GregorianCalendar();
gc.add(Calendar.DATE, -days);
return gc.getTime();
}
}
Implementacja jest dość oczywista. Na początku deklarujemy pole typu BookDao, do którego obiekt zostanie wstrzyknięty dzięki odpowiedniemu setterowi. Następnie używamy obiektu DAO, żeby wyciągnąć wszystkie książki z pliku. Ostatnim już etapem jest skopiowanie obiektów spełniających określone warunki do nowej listy.
Czas na ostatni krok – konfigurację.
Konfiguracja aplikacji opartej o Springa
najczęściej odbywa się w pliku XML
Konfiguracja warstw DAO i usług w Springu
Konfiguracja aplikacji opartej o Springa najczęściej odbywa się w pliku XML. Konwencja zakłada, że plik taki nosi nazwę applicationContext.xml, ale nie jest to regułą. Co więcej, nie jesteśmy wcale ograniczeni do jednego pliku konfiguracyjnego – możemy np. stworzyć osobne pliki dla warstw DAO, usług, czy bezpieczeństwa. W naszym prostym przykładzie w zupełności wystarczy jednak jeden plik o konwencjonalnej nazwie.
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans" (
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd">
<bean id="bookDao" class="dao.CsvBookDao">
(2)
<property name="csvBooksFile" value="/home/marcin/books.txt" />
(3)
</bean>
<bean id="bookService" class="service.BookService">
(4)
<property name="bookDao" ref="bookDao" />
</bean>
</beans>
Wstrzykiwanie przez setter lub konstruktor
Metoda, której używamy tutaj do wstrzykiwania zależności nazywa się wstrzykiwaniem przez setter. Spring pozwala także na wykorzystanie wstrzykiwania przez konstruktor.
Zamiast setterów, które ustawiają poszczególne pola klasy, możemy wykorzystać konstruktor z argumentami odpowiadającymi tym polom. W naszej klasie BookService moglibyśmy zastąpić setter przez następujący konstruktor:
public BookService(BookDao bookDao) {
this.bookDao = bookDao;
}
Musielibyśmy też zmodyfikować plik konfiguracyjny:
<bean id="bookService" class="service.BookService">
<constructor-arg ref="bookDao" />
</bean>
Które rozwiązanie stosować? To tak naprawdę kwestia gustu i wyczucia. Ogólna zasada mówi, żeby stosować wstrzykiwanie przez konstruktor dla pól, które są niezbędne dla poprawnego działania klasy, a wstrzykiwanie przez setter dla wszystkich pozostałych. Z drugiej strony używanie wyłącznie setterów pozwala na modyfikowanie wartości pól już po utworzeniu obiektu, co wpływa na elastyczność. Problem ten został dogłębniej omówiony w źródle (4).
Spring dostarcza wiele różnych schematów do konfigurowania różnych elementów. Tutaj (1) wykorzystaliśmy podstawowy schemat beans, służący do konfiguracji komponentów. W (2) definiujemy komponent klasy CsvBookDao o identyfikatorze bookDao. Klasa ta ma jedno pole – csvBookFile typu String. W (3) ustalamy wartość tego pola. Spring używa refleksji, żeby utworzyć obiekt żądanej klasy, a także zainicjować jej pole. Dzięki temu zabiegowi będziemy mogli w każdej chwili zmienić lokalizację pliku z książkami, co było naszym celem.
Analogicznie, w (4) definiujemy komponent klasy BookService, a jego pole bookDao inicjalizujemy referencją do uprzednio zdefiniowanego komponentu. Zwróćmy uwagę, że w atrybucie ref używamy tego samego ciągu znaków, co w atrybucie id wykorzystywanego obiektu.
Testujemy!
Jesteśmy właściwie u celu. Pozostaje przetestowanie zaimplementowanego rozwiązania. Ja wykorzystam bibliotekę JUnit 4, ale tak naprawdę nie ma to większego znaczenia – można nawet stworzyć prostą klasę, która po prostu wypisze oczekiwane pozycje książkowe.
package service;
//...pominięto importy
public class BookServiceTest {
@Test
public void getBooksLent30DaysAgo() throws Exception {
ApplicationContext appCtx = new ClassPathXmlApplicationContext(
"META-INF/spring/applicationContext.xml");
BookService bookService = (BookService) appCtx.getBean("bookService");
List<Book> booksLent30DaysAgo = bookService.findBooksLent30DaysAgo();
assertEquals(2, booksLent30DaysAgo.size());
assertEquals("Spring in Action", booksLent30DaysAgo.get(0).getTitle());
assertEquals("Spring in Practice", booksLent30DaysAgo.get(1).getTitle());
}
}
Najważniejsze są tutaj dwie pierwsze linie metody testującej. Na początku tworzymy obiekt klasy ClassPathXmlApplicationContext, do konstruktora której podajemy względną ścieżkę do pliku konfiguracyjnego. Dzięki tej klasie, możemy uzyskać referencję do każdego komponentu zdefiniowanego w pliku XML za pomocą wartości jego atrybutu id. Następnie za jej pomocą uzyskujemy referencję do naszej klasy usług, którą już możemy się posługiwać w standardowy sposób.
Podsumowanie
Zbudowaliśmy prostą aplikację wykorzystującą Spring Framework. Już teraz widać, że użycie DI sprawiło, iż jej moduły są lepiej odseparowane, a całość łatwiejsza w utrzymaniu. A to przecież tylko banalny przykład i raptem wierzchołek góry lodowej zwanej DI w Springu. Przed nami korzystanie z PropertyPlaceholderConfigurer, automatyczne wiązanie zależności oraz skanowanie komponentów, adnotacje i wiele więcej. Ale to temat na kolejny artykuł. Zainteresowanych poszerzeniem wiedzy już teraz zapraszam do listy źródeł.
Źródła
- Spring in Practice, Willie Wheeler, John Wheeler, Manning Publications – książka będąca inspiracją i podstawą do napisania tego artykułu
- Spring in Action, Craig Walls, Ryan Breidenbach, Manning Publications
- http://static.springsource.org/spring/docs/3.0.x/spring-framework-reference/html/
- http://martinfowler.com/articles/injection.html#ConstructorVersusSetterInjection
Source: http://www.javaexpress.pl/article/show/Spring__kontener_wstrzykiwania_zaleznosci