
Wzorce projektowe: Temporal Object
Gdy zaczynałem poznawać wzorce projektowe punktem wyjścia dla mnie były książki w stylu GoF, blogi, fora, itd. Znajdowałem tam przede wszystkim diagramy UML, oraz banalne przykłady kodu w stylu: fabryka pizzy, szablon algorytmu, budowniczy okienka. Mój kłopot polegał na tym, że chociaż rozumiałem o czym się do mnie pisze, to nie wiedziałem jak zastosować te koncepcje w moim kodzie. Moje projekty związane były np. ze sklepem internetowym lub systemem ankietowym i nijak to się miało do pizzy, algorytmów czy okienek. Brakowało mi przede wszystkim sensownej implementacji wzorca oraz konkretnych wskazówek jak i gdzie go użyć.
Po jakimś czasie zacząłem analizować źródła programów OpenSource takie jak Spring i apache-commons. Sęk w tym, że aby zrozumieć dobrze te projekty trzeba było wzorce projektowe wcześniej znać, a ja dopiero chciałem się ich nauczyć. Sporo mnie kosztowało rozgryzanie tego tematu.
W tej serii artykułów odpowiem choć na część w/w pytań. Będę: omawiał różne wzorce, podawał przykładowe implementacje i podpowiadał gdzie można ich użyć. Jeśli chodzi o sam sposób użycia czyli wprowadzanie wzorca do projektu i wykrywanie potencjalnych miejsc jego zastosowania w projekcie, to ten temat zostanie poruszony w wątku o refaktoringu (w najbliższej przyszłości).
Obiekty z historią
Wyobraźmy sobie, że należy stworzyć model obiektowy, który posłuży do zrealizowania funkcjonalności sklepu (taaa...wiem, że przykład mocno wyświechtany, lecz jakże użyteczny i skoro skojarzenia takie jak Hello world!, foo bar i Team-Member mocno zapadły w umysły rzesz programistów, więc i ja nie będę odstawał i posłużę się dobrze znanym przykładem rzeczonego sklepu).
Centralną klasą modelu będzie obiekt Order. Zakładając, że klient użytkujący sklep może zapisać stan swojego zamówienia, a następnie do niego wrócić, okazuje się, że warto śledzić historię jego... hmmm... niezdecydowania? W przypadku sklepu może być to pomocne np. podczas analizy aktywności klienta, na podstawie której można będzie mu w przyszłości zaproponować nowe produkty i usługi.
Postawiony problem można uogólnić następująco: stan danego obiektu może zmieniać się w czasie i należy zapewnić możliwość śledzenia historii zmian.
W tym miejscu zrób krótką przerwę, weź kartkę i długopis oraz zaproponuj przykładowe rozwiązanie omówionej kwestii.
Już masz? Świetnie, zatem porównaj je z dalszą częścią artykułu.
Temporal Object
Twoje rozwiązanie jest z pewnością wystarczające, lecz posłuchaj o innym, które jest na tyle często eksploatowane przez programistów, zostało określone mianem wzorca projektowego.
Intencją wzorca Temporal Object jest śledzenie zmian w obiekcie i udostępnianie ich na życzenie. Wzorzec ten jest również znany pod nazwami History on Self oraz Version History.
W przykładzie mamy do czynienia obiektem reprezentującym zamówienie. Sformułujmy wymagania co do funkcjonalności:
- usługa pracuje z obiektem zamówienia Order,
- zamówienie można dowolnie zmieniać,
- historia zmiana ma być śledzona i udostępniana na życzenie,
- dla celów raportowych, oprócz bieżących, należy zapamiętywać godzinowe milestones.
Spójrzmy na projekt rozwiązania:
Głównym konceptem jest wprowadzenie obiektu OrderVersion, który śledzi zmiany w zamówieni, tzn. dla każdej zmiany tworzony jest nowy obiekt OrderVersion. Sam obiekt klasy Order, z którego będą korzystały usługi jest niejako proxy bieżącej wersji zamówienia. Dodatkowo wprowadzona została klasa VersionHistory, której odpowiedzialnością jest zarządzanie historią zamówienia.
Całe piękno tego rozwiązania polega na tym, że usłudze udostępniony będzie obiekt Order, który powinien proksować API OrderVersion tyle, że pracuje zawsze na wersji bieżącej. Reszta przetwarzania jest ukryta przed klientem.
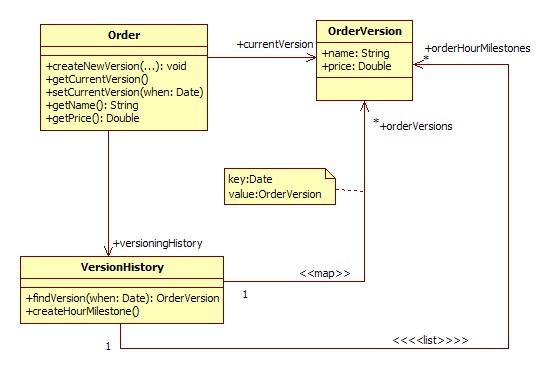
Zgodnie z założeniem tej serii artykułów przedstawiam również implementację wzorca.
public class Order implements Serializable {
private Long id;
private VersionHistory versioningHistory = new VersionHistory();
private OrderVersion currentVersion;
public void createNewVersion( String productId, String productName,
Double price ) {
OrderVersion orderVersion = new OrderVersion();
orderVersion.setCustomId( productId );
orderVersion.setName( productName );
orderVersion.setPrice( price );
versioningHistory.addOrderVersion(
orderVersion.getDate(), orderVersion );
currentVersion = orderVersion;
}
public void setCurrentVersionTo( Date when ) {
currentVersion = versioningHistory.findVersion( when );
}
protected OrderVersion getCurrentVersion() {
return currentVersion;
}
public String getCustomId() {
return getCurrentVersion().getCustomId();
}
public void setCustomId( String customId ) {
getCurrentVersion().setCustomId( customId );
}
//delegacje reszty getterów i setterów
}
public class VersionHistory implements Serializable {
private Map<Date, OrderVersion> orderVersions
= new HashMap<Date, OrderVersion>();
private List<OrderVersion> orderHourMilestones = new ArrayList<OrderVersion>();
public OrderVersion findVersion( Date date ) {
return orderVersions.get( date );
}
public void addOrderVersion( Date date, OrderVersion version ) {
orderVersions.put( date , version );
}
public void createHourMilestone() {
//...
}
}
public class OrderVersion implements Serializable {
private Long id;
private String customId;
private String name;
private Double price;
private Date date;
public OrderVersion() {
this.date = Utils.getNow();
}
}
//gettery i settery
A co z persystencją?
Kolejny problem, o który można potknąć się podczas nauki wzorców to kwestia związana z trwałym przechowywaniem danych. O ile w języku obiektowym można napisać niemal wszystko, również w bazie danych można stworzyć dowolnie złożone rozwiązanie to jednak sklejenie tego razem czasem nastręcza kłopotów. Dlatego, aby opis wzorca był kompletny zajmijmy się teraz trwałym przechowywaniem danych w relacyjnej bazie danych.
Domyślnie, używając dostarczycieli persystencji dla JPA, przyjmowana jest zasada, że jeden obiekt jest mapowany do jednej tabeli w bazie danych. Moim zdaniem przyjęcie takiej arbitralnej zasady prowadzi do bałaganu w bazie danych oraz do jej "niewyważenia". Niewyważenie rozumiem jako sytuację, gdzie poszczególne tabele przechowują nieproporcjonalnie dużą ilość danych, np. jedna tabela ma 2 kolumny oraz 10 wierszy, natomiast inna 20 kolumn i 10000 wierszy. Taka sytuacja w moim mniemaniu daje przesłanki do zastanowienia się, czy ta mała tabela jest potrzebna. Być może można znajdujące się w niej dane umieścić jako dodatkową kolumnę i innej tabeli i w ten sposób uprość zapytania SQL pracujące na bazie. Zaznaczam, że to moje prywatne zdanie.
Wykorzystując mapowania JPA umieścimy strukturę obiektową w dwóch tabelach: orders – przechowującej zamówienia oraz orders_versions – przechowującą wersje poszczególnych zamówień.
Schemat bazy danych będzie wyglądał jak na poniższym rysunku.

Wiersze z orders identyfikują poszczególne zamówienia oraz wskazują na jego bieżącą wersję. Natomiast wiersze z orders_versions przechowują dane na temat danej wersji. Dodatkowo każda wersja wskazuje na zamówienie do którego należy oraz, jeśli jest godzinowym milestonem, to wskazuje na właściciela. Na poziomie obiektowym pomiędzy obiektami Order oraz VersionHistory występuje relacja 1:1, zatem wiersze z orders identyfikują również obiekt VersionHistory. Z tego względu orders_versions posiada dodatkowe wskazanie na orders w postaci klucza ref_order_hour_milestone, określające, że dana wersja należy do historii wersji danego zamówienia.
Odpowiednie mapowania JPA wyglądają następująco:
@Entity @Table( name = "orders" )
@NamedQuery( name="Order.findAll", query="from Order" )
public class Order implements Serializable {
@Id
@GeneratedValue( strategy=GenerationType.AUTO )
private Long id;
@Embedded
private VersionHistory versioningHistory = new VersionHistory();
@OneToOne
@JoinColumn(name="ref_current_version")
private OrderVersion currentVersion;
}
@Embeddable
public class VersionHistory implements Serializable {
@OneToMany(cascade=CascadeType.ALL)
@MapKey( name="date" )
@JoinColumn( name="ref_order_history" )
private Map<Date, OrderVersion> orderVersions
= new HashMap<Date, OrderVersion>();
@OneToMany
@JoinColumn( name="ref_order_hour_milestone" )
private List<OrderVersion> orderHourMilestones = new ArrayList<OrderVersion>();
}
@Entity @Table( name = "orders_versions" )
public class OrderVersion implements Serializable {
@Id
@GeneratedValue( strategy=GenerationType.AUTO )
private Long id;
@Column( name="custom_id" )
private String customId;
private String name;
private Double price;
private Date date;
}
Jak można zauważyć pomiędzy tabelami orders a orders_versions występuje powiązanie dwukierunkowe.
Na wstępie tego rozdziału wspominałem o dbaniu o optymalność zapytań. Przeprowadziłem test i zapis jednego zamówienia z trzema wersjami powoduje wykonanie na bazie następujących zapytań SQL:
Hibernate: insert into orders (ref_current_version) values (?)
Hibernate: insert into orders_versions (custom_id, date, name, price) values (?, ?, ?, ?)
Hibernate: insert into orders_versions (custom_id, date, name, price) values (?, ?, ?, ?)
Hibernate: insert into orders_versions (custom_id, date, name, price) values (?, ?, ?, ?)
Hibernate: update orders set ref_current_version=? where id=?
Hibernate: update orders_versions set ref_order_hour_milestone=? where id=?
Hibernate: update orders_versions set ref_order_history=? where id=?
Hibernate: update orders_versions set ref_order_history=? where id=?
Hibernate: update orders_versions set ref_order_history=? where id=?
Zmieńmy jednak nieco schemat bazy danych przenosząc powiązanie zamówienia z jego bieżącą wersją do tabeli orders_versions.

Zmiana na w mapowaniach jest bardzo niewielka:
//...
public class Order implements Serializable {
//...
@OneToOne(mappedBy="parentOrder")
private OrderVersion currentVersion;
//...
public void createNewVersion( String productId, String productName,
Double price ) {
//..
orderVersion.setParentOrder( this );
}
}
//..
public class OrderVersion implements Serializable {
//..
@OneToOne
@JoinColumn(name="ref_order")
private Order parentOrder;
//..
}
Zestaw zapytań tym razem wygenerowany przez Hibernate wygląda następująco:
Hibernate: insert into orders values ( )
Hibernate: insert into orders_versions (custom_id, date, name, ref_order, price)
values (?, ?, ?, ?, ?)
Hibernate: insert into orders_versions (custom_id, date, name, ref_order, price)
values (?, ?, ?, ?, ?)
Hibernate: insert into orders_versions (custom_id, date, name, ref_order, price)
values (?, ?, ?, ?, ?)
Hibernate: update orders_versions set ref_order_hour_milestone=? where id=?
Hibernate: update orders_versions set ref_order_history=? where id=?
Hibernate: update orders_versions set ref_order_history=? where id=?
Hibernate: update orders_versions set ref_order_history=? where id=?
Zatem mamy o jedno zapytanie mniej. Czy to dużo? Trudno powiedzieć, aczkolwiek na każde tysiąc zapisów zamówienia do bazy danych mamy tysiąc zapytań mniej...
Podsumowując
Wzorca Temporal Object można użyć jeśli występuje potrzeba śledzenia i zapamiętywania zmian w modelu obiektowym. Używając narzędzi O\RM o trwałego zapisu danych, nie dajmy się zwieść iluzji, że programista może zapomnieć o bazie danych. Jeśli mamy na uwadze wydajność należy o tym pamiętać, zwłaszcza wtedy, gdy większość narzędzi ukrywa przed programistą złożoność swoich działań.


Nie ma jeszcze komentarzy.